引言
当你兴致勃勃地准备为自己的智能体接入GPT-4时,大概率会卡在第一个十字路口:到底是直接调用API,还是搞一套私有部署?调用API吧,担心网络不稳定、数据安全、长期费用不可控;私有部署吧,又怕硬件投入太大、技术门槛太高、维护起来麻烦。更让人头疼的是,网上教程要么只讲API怎么调,要么只吹私有化多安全,很少有人把两条路从技术实现到成本控制掰开揉碎了讲清楚。
这篇文章就是来填这个坑的。我会从最基础的API调用讲起,手把手带你跑通代码,再深入剖析私有部署的真实成本和实现路径。最重要的是,我会给你一套决策框架,帮你根据自身情况算出哪条路更划算。读完这篇文章,你不仅能自己动手让智能体用上GPT-4,更能成为一个懂技术算账的明白人。
前置准备
无论走哪条路,有几样东西你得先备好。首先是开发环境,一台能跑Python的电脑是必须的,建议装好Python 3.8以上版本,以及pip包管理工具。其次要懂一点基础编程,不需要多高深,能看懂Python代码、会运行脚本就够了。如果你是纯业务出身,也可以找个懂技术的朋友搭把手,或者直接用后面会提到的免代码工具。
如果你选择API路线,还需要准备一个OpenAI账号和API密钥——这可能是最折腾的一步,因为需要海外信用卡和特殊网络环境,具体怎么搞定我们会在后面细说。如果选择私有部署,那就要准备一台带GPU的服务器,至少要有16GB以上显存的显卡,比如RTX 3090或A10,否则跑不动像样的模型。
核心步骤
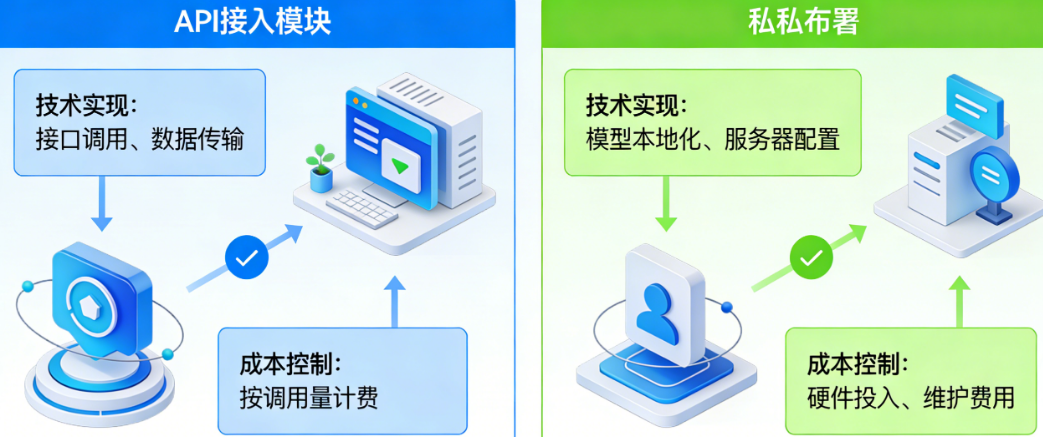
路径一:API接入——最快上手的实战方案
API接入的核心逻辑很简单:你把问题发给OpenAI的服务器,它在云端算完把结果返回给你。整个过程就像点外卖,你不需要自己做饭,只需要下单等餐就行。
第一步是获取API密钥。访问OpenAI官网(platform.openai.com),用海外手机号注册账号,然后进入API Keys页面创建新的密钥。这里要提醒一句:国内直连OpenAI极不稳定,很容易超时报错。解决办法是用代理,或者更省心的办法——使用国内的中转服务。像LaoZhang.ai这样的聚合平台,专门解决了国内访问和支付的问题,注册就能用,还支持微信支付宝充值,价格能做到官方的2.5折左右。
第二步是写代码调用。OpenAI官方提供了Python SDK,安装起来很简单:
bash
pip install openai
然后写几行代码就能跑通:
python
f rom openai import OpenAI
client = OpenAI(
api_key=”你的API密钥”,
base_url=”https://api.openai.com/v1″ # 如果用中转服务,这里换成他们的地址
)
response = client.chat.completions.create(
model=”gpt-4″,
messages=[
{“role”: “system”, “content”: “你是一个智能助手”},
{“role”: “user”, “content”: “你好,请介绍一下自己”}
]
)
print(response.choices[0].message.content)
跑通之后,你就可以把这个接口封装起来,接入自己的智能体了。如果想省掉写代码的步骤,也可以用Apifox这类工具,填好密钥直接调试,连代码都不用写。
第三步是成本控制。API是按token收费的,GPT-4的价格大约是输入5美元/百万token,输出15美元/百万token。一个普通问答大概消耗几百到上千token,算下来单次成本几分钱。但要注意,如果智能体频繁调用、处理长文本,或者用户量上来,账单会涨得很快。建议在代码里设置max_tokens限制,并开启用量监控告警,避免月底收到惊吓。
路径二:私有部署——自己当厨师的硬核方案
私有部署意味着你买一台高性能服务器,把模型文件下载下来跑在自己机器上。数据和计算都在本地,绝对安全,但也意味着所有问题都得自己扛。
第一步是硬件准备。想跑GPT-4级别的模型?醒醒,GPT-4根本没开源。你能私有部署的都是开源模型,比如Llama 3、Qwen等,它们的效果和GPT-4有差距,但对很多场景也够用。想跑Llama-3-70B这样的大模型,至少需要双卡3090或A100,硬件投入三五万起步。如果只想跑个7B或13B的小模型,一张RTX 3090也能凑合。
第二步是环境搭建。推荐用Ollama,这是目前最简单的本地部署工具。安装命令:
bash
curl -fsSL https://ollama.com/install.sh | sh
装好后拉取模型:
bash
ollama run llama3
它会自动下载并启动模型,然后你就能在命令行里聊天了。
第三步是提供API服务。Ollama自带API接口,默认在11434端口。写几行Python就能调用:
python
import requests
response = requests.post(
”http://localhost:11434/api/generate”,
json={
”model”: “llama3”,
”prompt”: “你好,请介绍一下自己”,
”stream”: False
}
)
print(response.json()[‘response’])
这样你的智能体就能通过本地API调用模型了,数据完全不出内网。
路径三:聚合API——取中间的最优解
如果你既想要GPT-4的能力,又不想折腾网络和支付,聚合API服务是很好的折中方案。这类服务相当于一个“大模型网关”,你用它一个API密钥,就能调用GPT-4、Claude、Gemini等各种模型。
使用方式和官方API完全一样,只需要改一下base_url:
python
client = OpenAI(
api_key=”聚合平台的密钥”,
base_url=”https://api.某平台.com/v1″ # 换成聚合服务的地址
)
之后你想用GPT-4就把model参数设成”gpt-4″,想用Claude就设成”claude-3-sonnet”,一套代码通吃所有模型。价格通常比官方便宜,因为平台有批量采购折扣,还能用人民币支付,对国内开发者极其友好。
常见问题与避坑指南
第一个坑是API密钥泄露。很多人把密钥直接硬编码在代码里,结果上传GitHub后被别人盗刷,一觉醒来欠费几千块。正确的做法是用环境变量存储密钥,或者在服务端做一层代理,客户端只请求你的后端,由后端保管密钥。
第二个坑是成本失控。API调用看起来单次便宜,但如果智能体被恶意刷量,或者代码里写了死循环,费用会飞速上涨。务必在代码里做限流,设置单用户调用上限,并在OpenAI后台开启用量限制和邮件告警。
第三个坑是私有部署的性能幻觉。很多人以为买了显卡就万事大吉,结果并发一上来就卡死。本地部署需要自己处理负载均衡、高可用、故障恢复,还要操心驱动更新、系统补丁。半夜两点服务器宕机,没人替你扛。
第四个坑是模型效果不符预期。私有部署的开源模型和GPT-4有肉眼可见的差距,尤其在逻辑推理和指令遵循上。如果业务对效果要求极高,私有部署可能无法满足,强行用只会让用户骂智能体“太笨”。
进阶技巧
想进一步优化成本?可以试试“混合调度”。日常简单问题用便宜的国产模型或小模型处理,只有复杂问题才调GPT-4。聚合平台支持这种动态切换,你可以在代码里根据问题长度或关键词做判断,选择不同模型。
想提升用户体验?务必开启流式输出(stream=True)。用户看到文字一个字一个字蹦出来,比等好几秒一次性看到全文感觉快得多。这点细微差别,可能决定用户愿不愿意继续用你的智能体。
想保障数据安全?如果必须用API但又怕数据泄露,可以做“脱敏处理”。把用户输入中的姓名、电话、地址替换成占位符,发给模型,拿到结果后再把真实信息填回去。这样既享受了云端模型的能力,又守住了隐私底线。

总结
让智能体用上GPT-4,没有放之四海皆准的唯一答案。API接入快、效果好、成本随用量波动,适合起步阶段和对效果要求高的场景;私有部署安全可控、长期成本低,适合数据敏感且预算充足的企业;聚合API则是折中优选,解决了网络和支付难题,性价比极高。

我的建议是:先走API路线(最好用聚合平台)快速跑通MVP,验证业务价值。等用户量上来、成本结构清晰了,再评估是否需要私有化。如果数据极度敏感,从一开始就做好脱敏,或者直接用私有部署的开源模型。技术选型从来不是纯技术问题,而是业务、成本、风险的综合权衡。希望这篇文章能帮你做出最适合自己的选择,让你的智能体早日用上最强的能力。

看完这篇技术拆解,无论是选择API接入还是私有部署,你都已经对让智能体用上GPT-4有了清晰认知。但如果自己动手仍觉得吃力,或者想找专业团队帮你快速落地,不妨来途傲科技试试。你可以在任务大厅发布需求,把业务场景、预算范围和期望的接入方式写清楚,平台上的专业服务商会主动对接;也可以去人才大厅搜索熟悉OpenAI API或大模型部署的开发者,直接沟通合作。拿不准主意时,逛逛服务大厅的商铺案例,看看同行们如何落地类似项目,从案例中获取灵感和信心。更可以学习威客攻略里的外包实战干货,或去一品商城直接购买现成的AI工具快速起步。从需求发布到技术落地,途傲科技汇聚的百万专业服务商,正等着用他们的技术实力,帮你把GPT-4真正用起来,用专业服务改变你的工作方式。

