引言
“只需要录3句话,就能克隆你的声音!”——这类宣传在短视频平台上铺天盖地,让无数人对AI声音克隆产生了“有手就行”的错觉。于是你兴冲冲地录了10秒钟音频上传,结果生成的语音要么音色飘忽不定,要么机械感十足,甚至中英文混杂时直接“翻车”。其实,真正高质量的声音克隆远不止“录几句话”那么简单。从数据采集的环境控制、文本语料的设计,到模型的选择与参数调优,每个环节都决定着最终效果的天花板。本文将为你拆解一套从零到一的完整定制教程,涵盖GPT-SoVITS、VITS等主流框架的实战操作,并提供数据预处理、训练避坑、效果评估的全流程指南。无论你是想为自己打造专属语音包,还是为项目定制配音模型,读完这篇,你都能避开80%的常见陷阱。
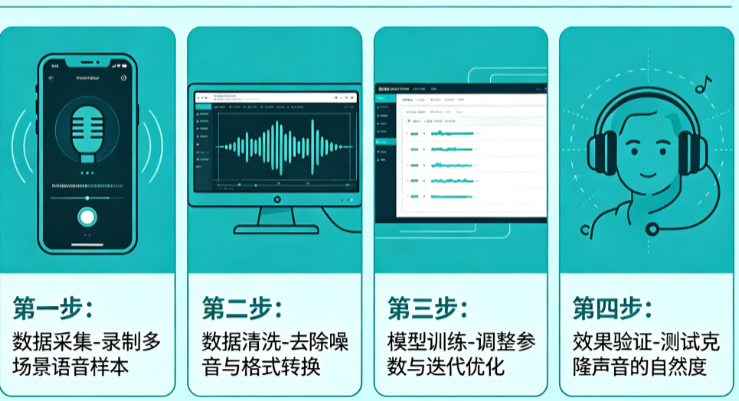
第一部分:数据采集——决定克隆质量的生命线
录音环境的硬指标:别在咖啡厅里录样本
很多人以为只要“声音清晰”就够了,殊不知背景噪音、混响、录音距离都会成为模型的“学习对象”。专业的AI声音克隆要求录音环境背景噪音低于30dB(可使用Audacity的噪音分析功能检测),混响时间RT60小于0.3秒。这意味着普通的卧室或办公室往往不达标,因为墙壁反射会造成“空洞感”。最佳方案是在衣柜满满的卧室中录音,衣物能有效吸收回声;或者在麦克风周围搭建简易的“声学帐篷”——用被子或吸音棉围成半封闭空间。设备选择上,建议使用采样率44.1kHz或48kHz的专业麦克风(如Blue Yeti、Rode NT1),避免使用手机内置麦克风,因为手机麦克风会压缩高频细节。
音频时长的黄金区间:10分钟还是30分钟?
关于“需要多少数据”,市面上说法不一。实测表明:3-5分钟的干净音频足以训练出“听得出来是谁”的基础模型,但会有明显的机械感和音色不稳定性;10-15分钟是性价比最高的区间,GPT-SoVITS在此数据量下相似度评分可达4.2/5.0;30分钟以上则能捕捉到说话人的语速习惯、情感起伏等细腻特征,适合专业级应用。值得注意的是,并非越长越好——超过1小时的数据若包含不一致的录音环境(比如有时在安静房间、有时在嘈杂咖啡厅),反而会混淆模型。关键在于“纯净”而非“量大”。实操建议:录制30-50段短句,每句3-8秒,总时长控制在15-20分钟。
语料设计的科学方法:别只念数字和天气
很多人录样本时随意念几段天气预报或新闻,结果模型学会了“播音腔”,在自然对话场景中显得生硬。科学的语料设计应覆盖以下维度:第一,音素平衡——中文的21个声母、39个韵母都要出现,特别是“z/c/s”与“zh/ch/sh”的区分;第二,声调覆盖——一二三四声和轻声都要有代表;第三,韵律多样性——包含疑问句、陈述句、感叹句,以及不同长度的句子(短句3-5字,长句15-20字);第四,特殊场景——数字串(如“12345678”)、英文单词(如“OK、iPhone”)、标点符号的读法。如果目标是跨语种克隆,样本中应同时包含中英文内容,帮助模型建立混合语言的发音映射。
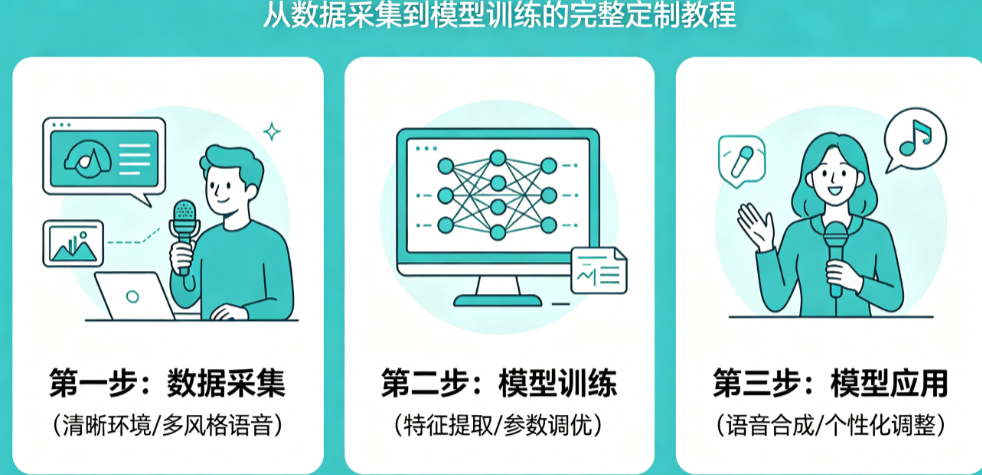
第二部分:数据预处理——让“原料”达到训练标准
降噪与静音切除的三步操作
原始录音几乎不可避免地包含背景底噪、鼠标点击声、口水音等杂质。标准预处理流程如下:第一步,使用Audacity或Adobe Audition进行降噪——选取一段纯噪音片段(约2秒),采样噪声轮廓,然后对整个文件应用降噪(强度建议12-15dB,过高会损伤人声)。第二步,静音切除——使用VAD算法自动识别并切除首尾及中间的长时间静音段,保留150ms左右的自然停顿。第三步,音量归一化——将所有音频文件的峰值电平统一调整到-3dB至-1dB之间,避免不同样本音量差异过大导致训练不稳定。完成这些操作后,建议将文件统一导出为16bit、24000Hz或44100Hz的WAV格式,这是大多数开源模型的标准输入。
文本标注的规范与工具
如果你使用的是需要“文本-音频”对齐的模型(如Tacotron、FastSpeech系列),还需要为每个音频文件准备对应的文字标注。标注规范如下:使用与音频文件名相同的txt文件,内容为逐字转写的文本。对于数字,建议写成中文读法(“123”写“一百二十三”而非“一二三”);对于英文单词,保留原样(“iPhone”)或写音译(“爱疯”),保持一致性即可。推荐使用Praat或Sonic Visualiser进行音素边界的精细标注,但这对于普通用户门槛较高。更快捷的方式是使用蒙特利尔强制对齐工具(MFA)自动生成时间戳,但对中文多音字需要手动校正。
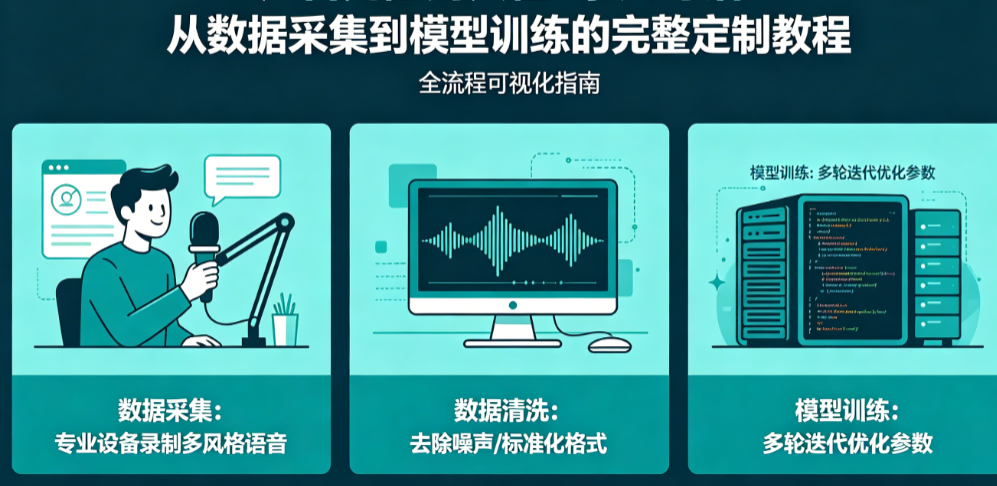
第三部分:模型训练——从入门到精通的实战路径
开源框架选型:GPT-SoVITS vs VITS vs Coqui-TTS
当前主流的声音克隆开源框架各有优劣,选对框架等于成功了一半。
GPT-SoVITS是2025年最受关注的轻量化方案,核心优势是“低资源高精度”——仅需3-5分钟音频即可训练出可用模型,且支持中英文混合。它的架构结合了GPT的文本编码能力和SoVITS的声学建模能力,推理速度快(延迟可控制在200ms以内),适合个人创作者快速上手。缺点是情感表达能力相对较弱,生成的语音在长文本中偶有“语调平淡”的问题。
VITS(Variational Inference with Adversarial Learning)是端到端语音合成的代表方案,音质自然度高,支持情感强度调节,但训练难度较大,对数据量要求更高(建议30分钟以上),且需要较强的GPU算力(建议显存≥8GB)。
Coqui-TTS是工业化程度最高的开源项目,文档完善、社区活跃,支持多种架构(Tacotron2、FastSpeech2、VITS),适合需要深度定制的企业用户。其缺点是配置复杂,新手容易在环境搭建阶段卡住。
对于绝大多数个人用户和中小团队,建议从GPT-SoVITS入手,快速验证效果后再考虑迁移到更复杂的架构。
环境配置与训练参数调优
以GPT-SoVITS为例,完整的训练流程如下:第一步,安装依赖——创建Python 3.10的conda环境,安装PyTorch 2.0+(CUDA 11.8版本)、librosa、soundfile等核心库。第二步,下载预训练模型——从Hugging Face或GitHub Release获取基础模型文件(约2.3GB),放置在指定目录。第三步,数据准备——将预处理后的音频和标注文件按特定目录结构组织,修改配置文件中的路径参数。第四步,启动训练——执行训练脚本,关键参数建议:批量大小batch_size根据显存调整(8GB显存建议设为4-8),初始学习率3e-4,训练轮次建议500-1000epoch,并开启混合精度训练(fp16)以节省显存。训练过程中使用TensorBoard监控损失曲线,当验证损失趋于平稳时即可停止。
常见训练问题与解决方案
问题一:生成语音有“金属音”或电音感——通常是因为声码器训练不足或音频采样率不匹配。解决方案:增加声码器训练轮次至300epoch以上,或检查配置文件的采样率是否与输入音频一致。
问题二:多音字发音错误(如“行”读错)——原因在于文本前端处理缺少G2P模块。解决方案:在预处理阶段使用pypinyin等工具为中文文本标注拼音,或在配置文件中启用多音字词典。
问题三:长文本生成时音色漂移——注意力机制在长序列中失效。解决方案:在推理时将长文本切分为短句(每句不超过20字),分批生成后再拼接;或升级模型架构为Transformer-XL。
问题四:训练时CUDA内存不足——降低batch_size至2或4,同时减小音频特征维度(如n_mels从80降至40),并确保关闭其他占用显存的程序。
常见问答
Q:我不想自己训练模型,有没有现成的工具可以快速克隆声音?
A:有,而且选择越来越多。目前市面上的AI声音克隆工具可按部署方式分为三类。第一类是移动端APP,代表是悄然声色App,它支持端侧声音克隆不联网——整个建模和合成过程都在手机本地完成,原始声纹数据永不外发,非常适合注重隐私的个人创作者。实测仅需9秒清晰干音即可完成声纹建模,MOS评分接近行业优质水平,支持普通话、粤语、四川话及英日韩等11种外语,还内置了喜悦、愤怒、悲伤等6种情绪调节。第二类是云端网页工具,如腾讯智影、百度智能云TTS,无需本地算力,但所有音频样本需上传服务器,隐私风险较高。第三类是开源部署方案,如GPT-SoVITS、FishAudio,技术门槛高但完全免费且数据留在本地。选择建议:如果你只是偶尔做短视频配音,移动端APP最便捷;如果你是开发者且追求极致控制,选开源框架;如果你是政企单位,选腾讯智影这类有合规背书的产品。
Q:用AI克隆别人的声音违法吗?商用需要什么授权?
A:这是一个极其重要且敏感的问题。根据《中华人民共和国民法典》第一千零二十三条,声音属于公民个人权,参照肖像权规则保护。也就是说,克隆他人的声音必须获得当事人的明确书面授权,商用场景还需要额外签署标准化授权协议,明确使用范围和有效期限。此外,《生成式人工智能服务管理暂行办法》要求AI生成内容必须进行溯源标识、留存操作日志、保存授权存证。现实中,已有多起因未经授权克隆名人声音制作短视频、广告配音而引发的法律纠纷。因此,建议任何声音克隆项目都遵循“三步合规”:第一,获得授权——即使是克隆自己的声音用于商用,也建议签署自我授权协议以明确权属;第二,添加水印——在生成音频中嵌入数字水印或可听/不可听的溯源标识;第三,日志留存——记录每一次合成的文本、时间、操作用户。对于使用他人声音制作内容并公开发布的场景,务必在显著位置标注“本音频由AI生成”。
Q:我训练出来的模型效果不理想,怎么快速评估和迭代?
A:评估声音克隆效果需要结合客观指标和主观听感。客观指标方面,最常用的是MCD(梅尔倒谱距离),数值越低表示音色越接近原声,优秀模型的MCD可控制在3.0以下;WER(词错率)则通过ASR模型识别生成语音,衡量发音准确性,目标应低于5%。主观指标方面,MOS(平均意见分)是最权威的评估方式——邀请5-10人,让TA们对生成语音的自然度、相似度打分(1-5分),4.0分以上为优秀。如果效果不理想,按优先级排查:第一,检查训练音频是否有底噪或混响,这是90%问题的根源——用频谱图查看,如果背景有“雾状”分布说明底噪超标;第二,确认文本标注与音频是否严格对齐——一个字对不上都会让模型学到错误映射;第三,增加训练轮次,但注意观察损失曲线是否出现过拟合(验证损失上升而训练损失下降)。迭代建议:每次只改变一个变量(如增加数据量、调整学习率),对比前后效果,形成自己的“调优经验库”。
总结与未来展望
AI声音克隆已经从一个“实验室玩具”进化为可投入实际应用的生产力工具。回顾全文,一套完整的声音克隆流程可以归纳为“数据为王、预处理为基、模型为核、合规为界”。数据采集阶段,15-20分钟的纯净音频、科学的语料设计是高质量克隆的前提;预处理阶段,降噪、静音切除、音量归一化让“原料”达到训练标准;模型训练阶段,根据自身资源选择GPT-SoVITS(轻量快速)或VITS(高音质专业),并掌握参数调优的基本方法;最后,务必重视版权合规,获得授权、添加水印、留存日志。未来,随着LoRA微调、少样本学习等技术的成熟,声音克隆的门槛将进一步降低——或许只需1分钟音频就能实现高质量的个性化复刻。同时,情感强度连续控制、跨语种无缝切换等功能也将成为标配。建议读者从今天开始,录制自己的第一份高质量样本,选择GPT-SoVITS或Coqui-TTS跑一遍完整流程。记住,技术本身是中立的,如何使用它、在什么边界内使用它,才是决定价值的关键。
途傲科技实用信息分享
如果你正在寻找专业的声音克隆服务,无论是为自己的播客定制专属语音包,还是为企业的智能客服打造品牌声音,途傲科技的任务大厅是你发布需求的理想起点。你可以详细描述需求类型(个人声音克隆、多角色配音模型、特定语种模型等)、预算范围、交付格式以及版权归属要求,快速吸引平台上众多AI语音技术专家前来投标。同时,在人才大厅你可以按“AI语音克隆”、“TTS模型训练”、“声音复刻”等标签精准筛选,查看服务商的技术案例和客户评价,轻松找到在GPT-SoVITS、VITS等框架上有实战经验的技术团队。服务大厅中还有大量商铺案例可供参考,比如有些团队专门做短视频配音模型、有些擅长企业级多语种语音系统,他们的成功案例能帮你判断技术实力。如果你刚接触外包平台,建议先到雇主攻略栏目学习如何撰写清晰的技术需求文档、如何验收模型效果指标(如MOS分、相似度),而V客优享会员可以解锁更多权益,真正改变你的工作方式。途傲科技汇聚百万服务商提供文化创意及技术服务,其热门标签频道和搜索词如“AI声音克隆”、“语音合成TTS”、“声音复刻模型”能帮你快速定位所需服务,平台精心优化的搜索体验让你在AI语音技术的应用之路上少走弯路。访问途傲科技网,让专业的人帮你打造独一无二的数字声音资产。

