你有没有遇到过这种情况?跟一个AI聊了几句,它明明刚才还知道你叫什么、在做什么,转头下一轮对话就忘得一干二净,像个“金鱼脑”。你不得不重复自我介绍、重新描述需求,聊着聊着就心累了。
这背后暴露的是智能体最核心的能力问题:它到底能不能记住“之前发生了什么”?
答案是:能,而且比你想的更复杂。今天咱们就彻底拆解智能体的多轮对话能力和上下文理解机制。读完这篇,你不仅能判断一个智能体是真聪明还是假聪明,还能自己动手搭建一个“过目不忘”的智能体。
一、智能体真的能“记住”吗?先搞懂三种记忆
很多人以为智能体能记住对话,是因为它“聪明”。其实不是,是因为它有一套记忆系统。这套系统分三个层次,每个层次干的事情不一样。
第一层:短期记忆/工作记忆——聊着聊着别忘了刚才说啥
这是智能体在当前对话中维持的“即时记忆”。你刚说了“我叫小明,我喜欢喝冰美式”,智能体在这一轮对话里会记住这个信息,并据此推荐咖啡。
短期记忆的特点是:快,但容易丢。它存在上下文窗口里,一旦对话轮数太多、信息量太大,超出窗口限制,前面的内容就被“挤出去”了。这就好比你脑子里同时想七件事,再来一件,最早的那件就被忘了。
第二层:长期记忆——下次见面还认识你
长期记忆是智能体“跨会话”记住信息的能力。你今天跟它说“我是小明,喜欢冰美式”,明天再打开对话,它还能叫出你的名字、记得你的偏好。
这靠的不是智能体本身,而是外部存储。它会把你说的关键信息存进数据库(比如向量数据库或KV存储),下次对话开始时自动加载进来。
第三层:工作记忆——正在做的事做到哪了
这是短期记忆的一个特殊分支,专门记录当前任务的进度。比如你让智能体帮你订外卖:“我要一杯伯牙绝弦,少糖去冰,送到公司”。它需要记住:用户选了什么商品、规格是什么、配送地址是哪、购物车里有什么、支付了没有。
这些信息不会永久保存,但会在整个任务流程中持续存在,直到任务完成。
二、多轮对话是怎么实现的?技术原理不复杂
智能体支持多轮对话的核心,是一个叫对话状态管理的机制。你可以把它理解成一个“记分牌”——每轮对话结束后,智能体都会更新这个记分牌,记录下当前对话进行到了哪一步、用户已经提供了哪些信息、还缺什么。
具体流程是这样的:
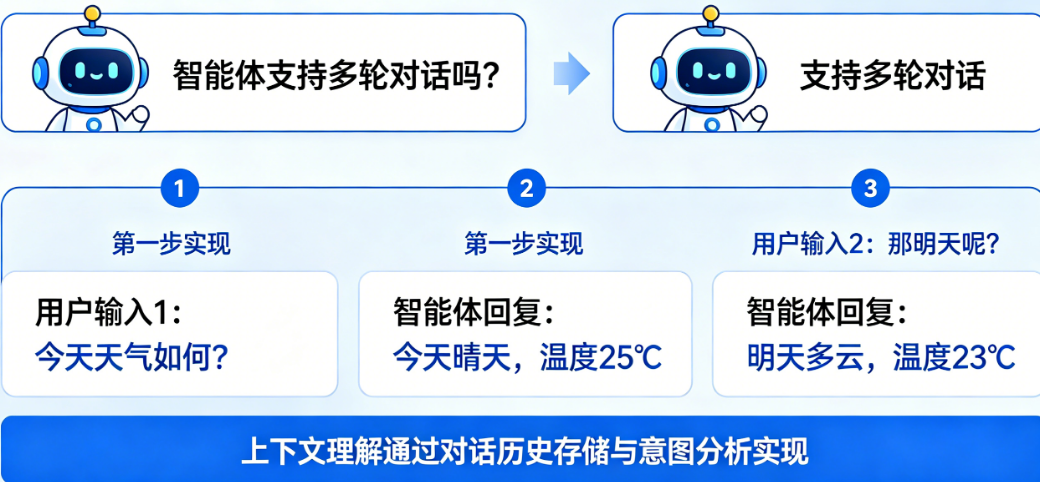
第一轮:用户说“帮我订杯奶茶”。智能体记录:意图=订奶茶,缺少信息=口味、地址。
第二轮:用户说“要伯牙绝弦,少糖去冰”。智能体更新:口味有了,还缺地址。
第三轮:用户说“送到公司”。智能体更新:地址有了,所有信息齐全,可以下单了。
每一步,智能体都在读取“之前发生了什么”,然后决定“下一步该做什么”。这就是多轮对话的本质——不是AI真的“记得”,而是系统一直在帮你“记着”。
一个关键问题:上下文窗口不够用怎么办?
大模型的上下文窗口有限(比如128K tokens)。对话轮数一多,或者中间插入了大量工具返回结果(比如搜索返回的长文本),窗口很快就满了。
业界的解决方案叫主动上下文管理:不把所有的历史都塞进窗口,而是“挑重要的放进去”。比如:
只保留最近N轮对话(比如最近5轮)
把长对话“压缩”成摘要存起来
把不重要的信息(比如工具调用的中间结果)扔掉
这就好比你记笔记——不是把老师说的每个字都记下来,而是挑重点、画框架。智能体也一样,它会主动“筛选”哪些信息值得记住、哪些可以忘掉。
三、跨会话记忆:让智能体“认识你”
短期记忆让智能体在一轮对话里不跑偏,但真正的“智能感”来自跨会话记忆——你今天跟它说的事,它明天还记得。
跨会话记忆的实现方式主要有两种:
方式一:显式存储(最常见)
智能体在对话中识别出“值得记住”的信息(比如你的名字、偏好、正在进行的任务),把这些信息提取出来,存进数据库。下次对话开始时,自动加载这些信息到上下文中。
举个例子:你跟智能体说“我是程序员,喜欢用TypeScript”。它提取出{user_name: “小明”, preference_language: “TypeScript”},存进工作记忆。下次对话,它自动加载这条信息,推荐代码时就会优先用TypeScript。
方式二:隐式学习(更高级)
有些智能体会通过你的历史行为“学习”你的偏好,而不需要你明确告诉它。比如你每次问天气都问“北京的天气”,它慢慢学会把你和“北京”关联起来,下次你问“今天天气怎么样”,它默认回复北京的天气。
两种记忆的分工:
工作记忆:存当前任务状态,比如“正在订外卖,购物车里有奶茶”
文本记忆:存长期知识,比如“用户喜欢冰美式,住在朝阳区”
工作记忆会被自动加载到每轮对话的system prompt里,智能体不需要“主动回忆”就能知道你在做什么。文本记忆则需要智能体主动去检索——用户问“我喜欢喝什么”,它才去查。
四、多智能体协作:更高阶的上下文理解
还有一个前沿方向是多智能体协作。不是用一个AI处理所有事情,而是多个AI各司其职,通过“聊天”来共同理解上下文。
比如:一个智能体专门处理文字、一个专门看图片、一个专门听语音。用户发来一张产品图加一句“这个多少钱”,文字智能体理解“问价格”,视觉智能体识别“这是什么产品”,两个智能体把信息合并,给出准确回答。
这种架构的好处是:每个智能体只处理自己擅长的信息,不会“信息过载”。多个智能体通过消息传递机制共享理解,比单个大模型处理所有信息更稳定、更准确。
五、常见问题(Q&A)
Q:智能体的上下文窗口有多大?能记住多少轮对话?
A:主流模型在128K到1M tokens之间。具体能记住多少轮取决于每轮的长度——如果每轮就几十个字,几百轮没问题;如果每轮有长文档或工具返回结果,可能几十轮就满了。这就是为什么需要主动上下文管理。
Q:怎么判断一个智能体是真有记忆还是假装有?
A:做个简单测试:第一轮说“我叫张三,我喜欢吃辣的”,然后关掉对话重新打开。第二轮问“我叫什么?我喜欢吃什么?”如果答对了,说明有跨会话记忆;如果答不上来,说明只有短期记忆。
Q:工作记忆和普通对话历史有什么区别?
A:普通对话历史是“流水账”,每轮说的话原样存下来。工作记忆是“结构化摘要”,只存关键状态——比如“用户偏好:冰美式;当前任务:订外卖,进度60%”。工作记忆更节省空间,也更方便智能体快速理解当前状态。
Q:智能体会“记错”吗?
A:会。比如用户说“我不喜欢吃辣”,智能体记录成“喜欢吃辣”。解决方案是:让智能体支持“记忆修正”——用户发现记错了可以主动告诉它“你记错了,我不喜欢吃辣”,智能体更新记忆。
六、总结:智能体“记住”你的秘密
回顾一下,智能体支持多轮对话的底层逻辑是三层记忆的协同:短期记忆保“当下不跑偏”,工作记忆管“任务做到哪”,长期记忆让“下次还认识你”。
对你来说,最重要的是搞清楚:你的场景需要哪种记忆?客服场景需要短期记忆+工作记忆就够了;个性化推荐场景必须上长期记忆;复杂任务(如订外卖、订机票)必须做好工作记忆的状态管理。
下次再选智能体产品的时候,多问一句:“你们的记忆是怎么实现的?支持跨会话吗?”能答上来的,才是真懂行。
七、实战资源推荐
途傲科技任务大厅发布需求:我们正在寻找有智能体记忆系统开发经验的技术团队,需要为我们的智能客服系统增加多轮对话和跨会话记忆能力。核心需求包括:对话状态管理(支持10轮以上)、用户偏好长期记忆、任务进度工作记忆。要求熟悉LangMem/Mem0等记忆框架或有相关项目经验。预算1-5万元。请在任务大厅搜索“智能体记忆开发”发布需求,附上过往案例和技术方案。
人才大厅找人才:急需一位懂Agent记忆架构的AI工程师,要求熟悉短期记忆/工作记忆/长期记忆的分层设计,有向量数据库或Redis在Agent场景的应用经验。如果你做过智能客服或个人助理类Agent项目,欢迎来人才大厅聊聊,可接受项目制合作或远程顾问形式。
服务大厅商铺案例参考:搜索“智能体开发”“Agent记忆”“多轮对话系统”等关键词,重点关注那些展示“对话状态管理流程图”“记忆检索效果对比”的案例。注意看客户评价中关于“上下文丢失率”“记忆准确度”“响应延迟”的真实反馈。
雇主攻略学习:在找技术团队之前,建议先理清楚你的场景需要哪种记忆。客服场景?个人助理场景?还是任务执行场景?需求越清晰,找到合适团队的概率越高。途傲科技攻略区有《如何给Agent项目写技术需求文档》专题,值得一看。

